
اختيار النموذج الذي يناسب بياناتك بشكل أفضل

أصدرت OpenAI مؤخرًا جيلها الجديد من نماذج التضمين، والتي تسمى التضمين v3، والتي يصفونها بأنها نماذج التضمين الأكثر أداءً، مع أداء أعلى متعدد اللغات. تأتي النماذج في فئتين: فئة أصغر تسمى text-embedding-3-small، وواحد أكبر وأقوى يسمى text-embedding-3-large.
تم الكشف عن القليل جدًا من المعلومات المتعلقة بالطريقة التي تم بها تصميم هذه النماذج وتدريبها. كإصدار سابق لنموذج التضمين (ديسمبر 2022 مع فئة الطراز ada-002)، تختار OpenAI مرة أخرى نهجًا مغلق المصدر حيث لا يمكن الوصول إلى النماذج إلا من خلال واجهة برمجة التطبيقات المدفوعة.
ولكن هل العروض جيدة جدًا لدرجة أنها تستحق الدفع؟
الدافع وراء هذا المنشور هو إجراء مقارنة تجريبية لأداء هذه النماذج الجديدة مع نظيراتها مفتوحة المصدر. سنعتمد على سير عمل استرداد البيانات، حيث يجب العثور على المستندات الأكثر صلة في المجموعة بناءً على استعلام المستخدم.
سيكون مجموعتنا هي القانون الأوروبي للذكاء الاصطناعي، والذي هو حاليًا في مراحل التحقق النهائية. من الخصائص المثيرة للاهتمام في هذه المجموعة، إلى جانب كونها أول إطار قانوني على الإطلاق بشأن الذكاء الاصطناعي في جميع أنحاء العالم، أنها متاحة بـ 24 لغة. وهذا يجعل من الممكن مقارنة دقة استرجاع البيانات عبر عائلات مختلفة من اللغات.
سيمر المنشور بالخطوتين الرئيسيتين التاليتين:
- قم بإنشاء مجموعة بيانات أسئلة/أجوبة تركيبية مخصصة من مجموعة نصية متعددة اللغات
- قارن دقة OpenAI وأحدث نماذج التضمين مفتوحة المصدر في مجموعة البيانات المخصصة هذه.
الكود والبيانات اللازمة لإعادة إنتاج النتائج المعروضة في هذا المنشور متاحة في مستودع Github هذا. لاحظ أنه تم استخدام قانون الاتحاد الأوروبي للذكاء الاصطناعي كمثال، ويمكن تكييف المنهجية المتبعة في هذا المنشور مع مجموعة بيانات أخرى.
دعونا نبدأ أولاً بإنشاء مجموعة بيانات من الأسئلة والأجوبة (أسئلة وأجوبة) على البيانات المخصصة، والتي سيتم استخدامها لتقييم أداء نماذج التضمين المختلفة. إن فوائد إنشاء مجموعة بيانات مخصصة للأسئلة والأجوبة ذات شقين. أولاً، يتجنب هذا التحيز من خلال التأكد من أن مجموعة البيانات لم تكن جزءًا من تدريب نموذج التضمين، وهو ما قد يحدث في معايير مرجعية مثل MTEB. ثانيًا، يسمح بتكييف التقييم مع مجموعة محددة من البيانات، والتي يمكن أن تكون ذات صلة في حالة تطبيقات الاسترجاع المعززة (RAG) على سبيل المثال.
سوف نتبع العملية البسيطة التي يقترحها Llama Index في وثائقهم. يتم تقسيم الجسم أولاً إلى مجموعة من القطع. بعد ذلك، لكل قطعة، يتم إنشاء مجموعة من الأسئلة التركيبية عن طريق نموذج اللغة الكبير (LLM)، بحيث تكمن الإجابة في القطعة المقابلة. تم توضيح العملية أدناه:

يعد تنفيذ هذه الإستراتيجية أمرًا مباشرًا من خلال إطار بيانات LLM مثل Llama Index. يمكن إجراء تحميل النص وتقسيمه بسهولة باستخدام وظائف عالية المستوى، كما هو موضح في الكود التالي.
from llama_index.readers.web import SimpleWebPageReader
from llama_index.core.node_parser import SentenceSplitterlanguage = "EN"
url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206"
documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc])
parser = SentenceSplitter(chunk_size=1000)
nodes = parser.get_nodes_from_documents(documents, show_progress=True)
في هذا المثال، النص هو قانون الاتحاد الأوروبي بشأن الذكاء الاصطناعي باللغة الإنجليزية، وهو مأخوذ مباشرة من الويب باستخدام عنوان URL الرسمي هذا. نستخدم مسودة الإصدار اعتبارًا من أبريل 2021، حيث أن الإصدار النهائي ليس متاحًا بعد لجميع اللغات الأوروبية. في هذا الإصدار، يمكن استبدال اللغة الإنجليزية في عنوان URL بأي من اللغات الرسمية الأخرى للاتحاد الأوروبي البالغ عددها 23 لغة لاسترداد النص بلغة مختلفة (BG للغة البلغارية، وES للغة الإسبانية، وCS للغة التشيكية، وما إلى ذلك).

نستخدم كائن SentenceSplitter لتقسيم المستند إلى أجزاء مكونة من 1000 رمز مميز. بالنسبة للغة الإنجليزية، ينتج عن هذا حوالي 100 قطعة.
يتم بعد ذلك توفير كل قطعة كسياق للموجه التالي (الموجه الافتراضي المقترح في مكتبة Llama Index):
prompts={}
prompts["EN"] = """\
Context information is below.---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, generate only questions based on the below query.
You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination.
The questions should be diverse in nature across the document. Restrict the questions to the context information provided."
"""
يهدف الموجه إلى توليد أسئلة حول جزء المستند، كما لو كان المعلم يقوم بإعداد اختبار قادم. يتم تمرير عدد الأسئلة التي سيتم إنشاؤها لكل مجموعة كمعلمة “num_questions_per_chunk”، والتي قمنا بتعيينها على اثنين. يمكن بعد ذلك إنشاء الأسئلة عن طريق استدعاء generator_qa_embedding_pairs من مكتبة Llama Index:
from llama_index.llms import OpenAI
from llama_index.legacy.finetuning import generate_qa_embedding_pairsqa_dataset = generate_qa_embedding_pairs(
llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),
nodes=nodes,
qa_generate_prompt_tmpl = prompts[language],
num_questions_per_chunk=2
)
نحن نعتمد في هذه المهمة على وضع GPT-3.5-turbo-0125 من OpenAI، والذي يعد وفقًا لـ OpenAI النموذج الرئيسي لهذه العائلة، ويدعم نافذة سياق 16 كيلو بايت ومُحسَّنة للحوار (https://platform.openai.com/ مستندات/نماذج/gpt-3-5-turbo).
يحتوي الكائن الناتج “qa_dataset” على أزواج الأسئلة والأجوبة (القطع). كمثال على الأسئلة التي تم إنشاؤها، إليك نتيجة السؤالين الأولين (والتي تكون “الإجابة” لها هي الجزء الأول من النص):
1) ما هي الأهداف الرئيسية لمقترح لائحة تنظيم القواعد المنسقة للذكاء الاصطناعي (قانون الذكاء الاصطناعي) وفقاً للمذكرة التوضيحية؟
2) كيف يهدف مقترح اللائحة التنظيمية للذكاء الاصطناعي إلى معالجة المخاطر المرتبطة باستخدام الذكاء الاصطناعي مع تعزيز استيعاب الذكاء الاصطناعي في الاتحاد الأوروبي، على النحو المبين في معلومات السياق؟
يعتمد عدد المقاطع والأسئلة على اللغة، ويتراوح من حوالي 100 قطعة و200 سؤال للغة الإنجليزية، إلى 200 قطعة و400 سؤال للغة المجرية.
تتبع وظيفة التقييم لدينا وثائق مؤشر اللاما وتتكون من خطوتين رئيسيتين. أولاً، يتم تخزين التضمينات الخاصة بجميع الإجابات (أجزاء المستند) في VectorStoreIndex من أجل استرجاعها بكفاءة. بعد ذلك، تقوم وظيفة التقييم بتكرار جميع الاستعلامات، واسترداد أهم المستندات المتشابهة، ويتم تقييم دقة الاسترجاع من حيث MRR (متوسط الرتبة المتبادلة).
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):
# Get corpus, queries, and relevant documents from the qa_dataset object
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs# Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddings
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(
nodes, embed_model=embed_model, insert_batch_size=insert_batch_size
)
retriever = index.as_retriever(similarity_top_k=top_k)
# Prepare to collect evaluation results
eval_results = []
# Iterate over each query in the dataset to evaluate retrieval performance
for query_id, query in tqdm(queries.items()):
# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documents
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
# Check if the expected document was among the retrieved documents
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query
# Calculate the Mean Reciprocal Rank (MRR) and append to results
if is_hit:
rank = retrieved_ids.index(expected_id) + 1
mrr = 1 / rank
else:
mrr = 0
eval_results.append(mrr)
# Return the average MRR across all queries as the final evaluation metric
return np.average(eval_results)
يتم تمرير نموذج التضمين إلى وظيفة التقييم عن طريق وسيطة `embed_model`، والتي تكون بالنسبة لنماذج OpenAI عبارة عن كائن OpenAIEmbedding تمت تهيئته باسم النموذج وبُعد النموذج.
from llama_index.embeddings.openai import OpenAIEmbeddingembed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
ال dimensions يمكن لمعلمة API تقصير عمليات التضمين (أي إزالة بعض الأرقام من نهاية التسلسل) دون أن يفقد التضمين خصائصه التي تمثل المفهوم. تقترح OpenAI على سبيل المثال في إعلانها أنه وفقًا لمعيار MTEB، يمكن تقصير التضمين إلى حجم 256 بينما لا يزال يتفوق على التضمين غير المختصر. text-embedding-ada-002 التضمين بحجم 1536.
قمنا بتشغيل وظيفة التقييم على أربعة نماذج مختلفة لتضمين OpenAI:
- نسختين من
text-embedding-3-large: أحدهما بأقل بعد ممكن (256)، والآخر بأعلى بعد ممكن (3072). تسمى هذه “OAI-large-256″ و”OAI-large-3072”. - OAI-صغير: ال
text-embedding-3-smallنموذج التضمين، بأبعاد 1536. - OAI-ada-002: الإرث
text-embedding-ada-002نموذج بأبعاد 1536.
تم تقييم كل نموذج بأربع لغات مختلفة: الإنجليزية (EN)، الفرنسية (FR)، التشيكية (CS) والمجرية (HU)، والتي تغطي أمثلة من اللغة الجرمانية والرومانسية والسلافية والأورالية، على التوالي.
embeddings_model_spec = {
}embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256}
embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072}
embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536}
embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
# Get model
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
# Assess embedding score (in terms of MRR)
score = evaluate(qa_dataset, embed_model)
results.append([language, model_name, score])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])
تم الإبلاغ عن الدقة الناتجة من حيث MRR أدناه:

كما هو متوقع، بالنسبة للنموذج الكبير، تمت ملاحظة أداء أفضل مع حجم التضمين الأكبر البالغ 3072. وبالمقارنة مع نماذج Ada الصغيرة والقديمة، فإن النموذج الكبير أصغر مما كنا نتوقعه. للمقارنة، نورد أدناه أيضًا الأداء الذي حصلت عليه نماذج OpenAI وفقًا لمعيار MTEB.

ومن المثير للاهتمام أن نلاحظ أن الاختلافات في الأداء بين النماذج الكبيرة والصغيرة ونماذج Ada أقل وضوحًا في تقييمنا عنها في معيار MTEB، مما يعكس حقيقة أن متوسط الأداء الملحوظ في المعايير الكبيرة لا يعكس بالضرورة تلك التي تم الحصول عليها على أساس مخصص مجموعات البيانات.
إن الأبحاث مفتوحة المصدر حول عمليات التضمين نشطة للغاية، ويتم نشر نماذج جديدة بانتظام. مكان جيد للبقاء على اطلاع بأحدث النماذج المنشورة هو Hugging Face 😊 لوحة المتصدرين لـ MTEB.
للمقارنة في هذه المقالة، اخترنا مجموعة من أربعة نماذج تضمين تم نشرها مؤخرًا (2024). وكانت معايير الاختيار هي متوسط درجاتهم في لوحة المتصدرين لـ MTEB وقدرتهم على التعامل مع البيانات متعددة اللغات. ويرد أدناه ملخص للخصائص الرئيسية للنماذج المختارة.
- E5-ميسترال-7B-إرشاد (E5-mistral-7b): تمت تهيئة نموذج التضمين E5 هذا من Microsoft من Mistral-7B-v0.1 وتم ضبطه على مزيج من مجموعات البيانات متعددة اللغات. يعمل النموذج بشكل أفضل على لوحة المتصدرين MTEB، ولكنه أيضًا الأكبر على الإطلاق (14 جيجابايت).
- متعدد اللغات-e5-كبير-تعليمات (ML-E5-large): نموذج E5 آخر من Microsoft، يهدف إلى التعامل بشكل أفضل مع البيانات متعددة اللغات. تمت تهيئته من xlm-roberta-large وتم تدريبه على مزيج من مجموعات البيانات متعددة اللغات. إنه أصغر بكثير (10 مرات) من E5-Mistral، ولكنه يحتوي أيضًا على حجم سياق أقل بكثير (514).
- بجي-M3: تم تصميم النموذج من قبل أكاديمية بكين للذكاء الاصطناعي، وهو نموذج متطور لتضمين البيانات متعددة اللغات، ويدعم أكثر من 100 لغة عمل. لم يتم قياسه بعد على لوحة المتصدرين MTEB اعتبارًا من 22/02/2024.
- nomy-embed-text-v1 (Nomic-Embed): تم تصميم النموذج بواسطة Nomic، ويطالب بأداء أفضل من OpenAI Ada-002 وtext-embedding-3-small بينما يبلغ حجمه 0.55 جيجابايت فقط. ومن المثير للاهتمام أن النموذج هو الأول الذي يمكن إعادة إنتاجه وتدقيقه بالكامل (البيانات المفتوحة وكود التدريب مفتوح المصدر).
يشبه الكود الخاص بتقييم هذه النماذج مفتوحة المصدر الكود المستخدم في نماذج OpenAI. يكمن التغيير الرئيسي في مواصفات النموذج، حيث يجب تحديد تفاصيل إضافية مثل الحد الأقصى لطول السياق وأنواع التجميع. ثم نقوم بتقييم كل نموذج لكل لغة من اللغات الأربع:
embeddings_model_spec = {
}embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token',
'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}}
embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
print("Processing model : "+str(model_spec))
# Get model
tokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])
embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs'])
if model_name=="Nomic-Embed":
embed_model.to('cuda')
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
start_time_assessment=time.time()
# Assess embedding score (in terms of hit rate at k=5)
score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type'])
# Get duration of score assessment
duration_assessment = time.time()-start_time_assessment
results.append([language, model_name, score, duration_assessment])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])
تم الإبلاغ عن الدقة الناتجة من حيث MRR أدناه.

اتضح أن BGE-M3 يقدم أفضل الأداء، يليه في المتوسط ML-E5-Large، وE5-mistral-7b، وNomic-Embed. لم يتم بعد قياس نموذج BGE-M3 على لوحة المتصدرين لـ MTEB، وتشير نتائجنا إلى أنه يمكن أن يحتل مرتبة أعلى من النماذج الأخرى. ومن المثير للاهتمام أيضًا ملاحظة أنه على الرغم من تحسين BGE-M3 للبيانات متعددة اللغات، إلا أنه يعمل أيضًا بشكل أفضل للغة الإنجليزية مقارنة بالنماذج الأخرى.
بالإضافة إلى ذلك، نقوم بالإبلاغ عن أوقات المعالجة لكل نموذج تضمين أدناه.

إن الطراز E5-mistral-7b، الذي يزيد حجمه عن النماذج الأخرى بعشر مرات، هو بلا مفاجأة أبطأ نموذج على الإطلاق.
دعونا نضع أداء النماذج الثمانية التي تم اختبارها جنبًا إلى جنب في شكل واحد.
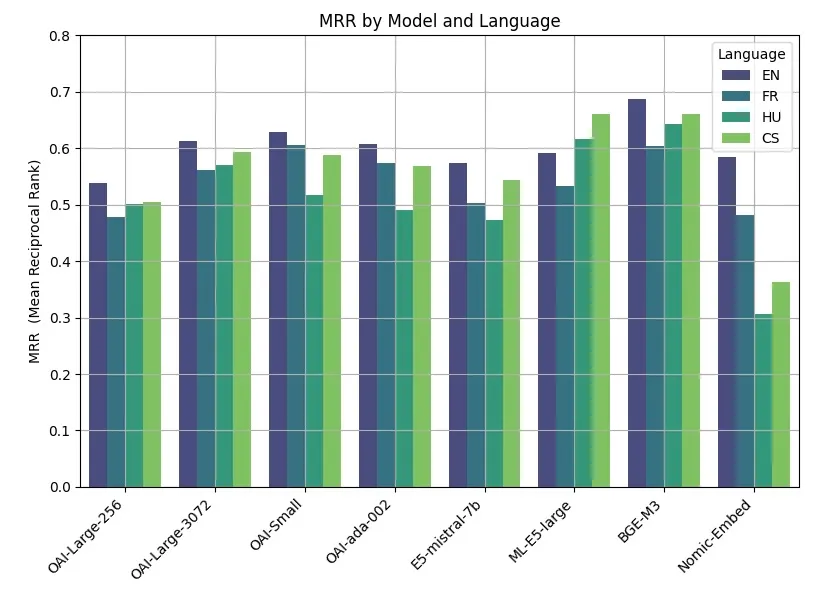
الملاحظات الرئيسية من هذه النتائج هي:
- تم الحصول على أفضل العروض من خلال النماذج مفتوحة المصدر. وبرز نموذج BGE-M3، الذي طورته أكاديمية بكين للذكاء الاصطناعي، باعتباره النموذج الأفضل أداءً. يحتوي النموذج على نفس طول السياق مثل نماذج OpenAI (8K)، بحجم 2.2 جيجابايت.
- الاتساق عبر نطاق OpenAI. كان أداء نماذج OpenAI الكبيرة (3072) والصغيرة والقديمة متشابهًا جدًا. ومع ذلك، أدى تقليل حجم التضمين للنموذج الكبير (256) إلى تدهور الأداء.
- حساسية اللغة. حققت جميع الطرز تقريبًا (باستثناء ML-E5-large) أفضل أداء في اللغة الإنجليزية. وقد لوحظت اختلافات كبيرة في الأداء في لغات مثل التشيكية والمجرية.
هل يجب عليك بالتالي اختيار اشتراك OpenAI مدفوع، أو استضافة نموذج تضمين مفتوح المصدر؟
أدت المراجعة الأخيرة لأسعار OpenAI إلى جعل الوصول إلى واجهة برمجة التطبيقات (API) الخاصة بها أقل تكلفة بكثير، حيث تبلغ التكلفة الآن 0.13 دولارًا لكل مليون رمز مميز. وبالتالي فإن التعامل مع مليون استفسار شهريًا (بافتراض أن كل استعلام يتضمن حوالي ألف رمز مميز) سيكلف حوالي 130 دولارًا. اعتمادًا على حالة الاستخدام الخاصة بك، قد لا يكون استئجار خادم التضمين الخاص بك وصيانته أمرًا فعالاً من حيث التكلفة.
ومع ذلك، فإن فعالية التكلفة ليست الاعتبار الوحيد. قد يلزم أيضًا أخذ عوامل أخرى في الاعتبار، مثل زمن الوصول والخصوصية والتحكم في سير عمل معالجة البيانات. توفر النماذج مفتوحة المصدر ميزة التحكم الكامل في البيانات، وتعزيز الخصوصية والتخصيص. من ناحية أخرى، تمت ملاحظة مشكلات زمن الاستجابة مع واجهة برمجة تطبيقات OpenAI، مما أدى في بعض الأحيان إلى أوقات استجابة ممتدة.
في الختام، فإن الاختيار بين النماذج مفتوحة المصدر والحلول المسجلة الملكية مثل OpenAI لا يصلح لإجابة واضحة. توفر التضمينات مفتوحة المصدر خيارًا مقنعًا، حيث تجمع بين الأداء والتحكم الأكبر في البيانات. على العكس من ذلك، قد تظل عروض OpenAI جذابة لأولئك الذين يمنحون الأولوية للراحة، خاصة إذا كانت المخاوف المتعلقة بالخصوصية ثانوية.
ملحوظات:




